Spiideo Revolutionizes Sports Broadcasting with Ambitious AI Automation Goals
3 Important Considerations in DDPG Reinforcement Algorithm

Deep Deterministic Policy Gradient (DDPG) is a Reinforcement learning algorithm for learning continuous actions. You can learn more about it in the video below on YouTube:
https://youtu.be/4jh32CvwKYw?si=FPX38GVQ-yKESQKU
Here are 3 important considerations you will have to work on while solving a problem with DDPG. Please note that this is not a How-to guide on DDPG but a what-to guide in the sense that it only talks about what areas you will have to look into.
Noise
Ornstein-Uhlenbeck
The original implementation/paper on DDPG mentioned using noise for exploration. It also suggested that the noise at a step depends on the noise in the earlier step. The implementation of this noise is the Ornstein-Uhlenbeck process. Some people later got rid of this constraint about the noise and just used random noise. Based on your problem domain, you may not be OK to keep noise at a step related to the noise at the earlier step. If you keep your noise at a step dependent on the noise at the earlier step, then your noise will be in one direction of the noise mean for some time and may limit the exploration. For the problem I am trying to solve with DDPG, a simple random noise works just fine.
Size of Noise
The size of noise you use for exploration is also important. If your valid action for your problem domain is from -0.01 to 0.01 there is not much benefit by using a noise with a mean of 0 and standard deviation of 0.2 as you will let your algorithm explore invalid areas using noise of higher values.
Noise decay
Many blogs talk about decaying the noise slowly during training, while many others do not and continue to use un-decayed during training. I think a well-trained algorithm will work fine with both options. If you do not decay the noise, you can just drop it during prediction, and a well-trained network and algorithm will be fine with that.
Soft update of the target networks
As you update your policy neural networks, at a certain frequency, you will have to pass a fraction of the learning to the target networks. So there are two aspects to look at here — At what frequency do you want to pass the learning (the original paper says after every update of the policy network) to the target networks and what fraction of the learning do you want to pass on to the target network? A hard update to the target networks is not recommended, as that destabilizes the neural network.
But a hard update to the target network worked fine for me. Here is my thought process — Say, your learning rate for the policy network is 0.001 and you update the target network with 0.01 of this every time you update your policy network. So in a way, you are passing 0.001*0.01 of the learning to the target network. If your neural network is stable with this, it will very well be stable if you do a hard update (pass all the learning from the policy network to the target network every time you update the policy network), but keep the learning rate very low.
Neural network design
While you are working on optimizing your DDPG algo parameters, you also need to design a good neural network for predicting action and value. This is where the challenge lies. It is difficult to tell if the bad performance of your solution is due to the bad design of the neural network or an unoptimized DDPG algo. You will need to keep optimizing on both fronts.
While a simpleton neural network can help you solve Open AI gym problems, it will not be sufficient for a real-world complex problem. The principle I follow while designing a neural network is that the neural network is an implementation of your (or the domain expert’s) mental framework of the solution. So you need to understand the mental framework of the domain expert in a very fundamental manner to implement it in a neural network. You also need to understand what features to pass to the neural network and how to engineer the features in a way that the neural network can interpret them to successfully predict. And that is where the art of the craft lies.
I still have not explored discount rate (which is used to discount rewards over time-steps) and have not yet developed a strong intuition (which is very important) about it.
I hope you liked the article and did not find it overly simplistic or stupid. If liked it, please do not forget to clap!
3 Important Considerations in DDPG Reinforcement Algorithm was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Will AI Take Big Part in Lok Sabha Election
Reliable AI Model Tuning : Leveraging HNSW Vector with Firebase Genkit
Instant AI Model Tuning: Leveraging HNSW Vector with Firebase Genkit for Retrieval-Augmented Generation

The rapid advancements in Generative AI have transformed how we interact with technology, enabling more intelligent and context-aware systems. A critical component in achieving this is Retrieval-Augmented Generation (RAG), which allows AI models to pull in specific contexts or knowledge without the need to build or retrain models from scratch.
One of the most efficient technologies facilitating this is the Hierarchical Navigable Small World (HNSW) graph-based vector index. This article will guide you through the setup and usage of the Genkit HNSW Vector index plugin to enhance your AI applications, ensuring they are capable of providing highly accurate and context-rich responses.
Understanding Generative AI

For those who still do not understand what generative AI, feel free to read about it here!
Fine-tuning in Generative AI
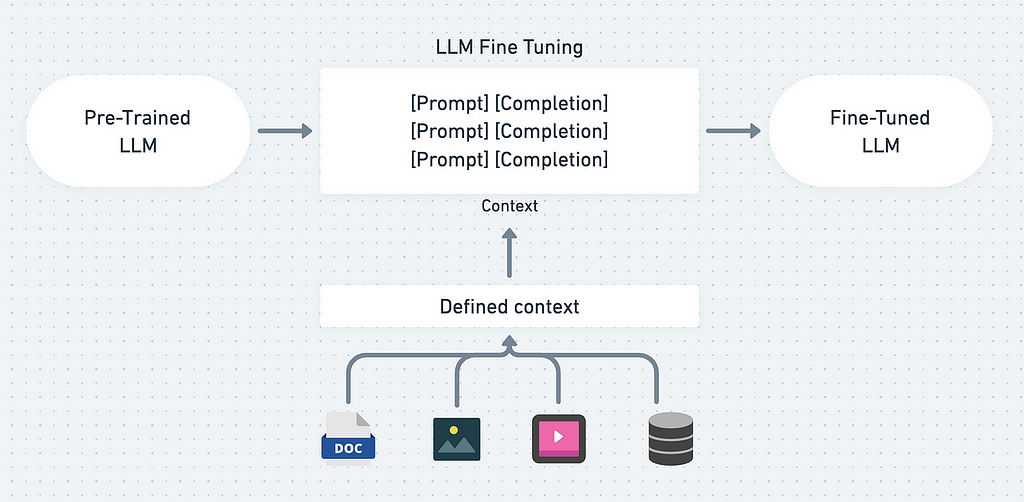
Fine-tuning is a great method to improve your AI Model! with fine-tuning, you can add more knowledge and context for the AI Model.
There are various ways to implement fine-tuning, so it is important to know how we can leverage the AI Model maximally to fit our application requirements.
If you want to read more about them and its differences, you can read more here!
Now, that we know about Generative AI and Fine-Tuning, we will learn how we can implement Retrieval-Augmented Generation (RAG) using HNSW Index.
Implementing Retrieval-Augmented Generation (RAG)
Generative AI’s capabilities can be significantly enhanced when integrated with an HNSW vector index to implement the RAG mechanism. This combination allows the AI to retrieve and utilize specific contextual information efficiently, leading to more accurate and contextually relevant outputs.
Example Use Case
Consider a restaurant application or website where specific information about your restaurants, including addresses, menu lists, and prices, is integrated into the AI’s knowledge base. When a customer inquires about the price list of your restaurant in Surabaya City, the AI can provide precise answers based on the enriched knowledge.
Example Conversation with AI Model :
You: What are the new additions to the menu this week?
AI: This week, we have added the following items to our menu:
- Nasi Goreng Kampung - Rp. 18.000
- Sate Ayam Madura - Rp. 20.000
- Es Cendol - Rp. 10.000
With RAG we can achieve a very detailed and specific response from the AI Model.
Now, to implement this, we will be using :
- HNSW Vector
We will convert our defined data into a Vector index, where it can be understood by the AI Model so that the AI Model can have a better response. - Firebase Genkit (Our special guest! :D)
We will use this to demonstrate this Retrieval-Augmented Generation (RAG) using HNSW Vector index and Gemini AI Model.
Implementing HNSW Vector index
What is HNSW?
HNSW stands for Hierarchical Navigable Small World, a graph-based algorithm that excels in vector similarity search. It is renowned for its high performance, combining fast search speeds with exceptional recall accuracy. This makes HNSW an ideal choice for applications requiring efficient and accurate retrieval of information based on vector embeddings.
Why Choose HNSW?
- Simple Setup: HNSW offers a straightforward setup process, making it accessible even for those with limited technical expertise.
- Self-Managed Indexes: Users have the flexibility to handle and manage the vector indexes on their servers.
- File-Based Management: HNSW allows the management of vector indexes as files, providing ease of use and portability, whether stored as blob or stored in a database.
- Compact and Efficient: Despite its small size, HNSW delivers fast performance, making it suitable for various applications.
Learn more about HNSW.
Implementing Firebase Genkit

What is Firebase Genkit?
Firebase Genkit is a powerful suite of tools and services designed to enhance the development, deployment, and management of AI-powered applications. Leveraging Firebase’s robust backend infrastructure.
Genkit simplifies the integration of AI capabilities into your applications, providing seamless access to machine learning models, data storage, authentication, and more.
Key Features of Firebase Genkit
- Seamless Integration: Firebase Genkit offers a straightforward integration process, enabling developers to quickly add AI functionalities to their apps without extensive reconfiguration.
- Scalable Infrastructure: Built on Firebase’s highly scalable cloud infrastructure, Genkit ensures that your AI applications can handle increased loads and user demands efficiently.
- Comprehensive Suite: Genkit includes tools for data management, real-time databases, cloud storage, authentication, and more, providing a comprehensive solution for AI app development.
Enhancing Generative AI with Firebase Genkit
By integrating Firebase Genkit with your Generative AI applications, you can significantly enhance the functionality and user experience. Here’s how Firebase Genkit contributes to the effectiveness of AI applications:
- Real-Time Data Handling: Firebase Genkit’s real-time database allows for the immediate update and retrieval of data, ensuring that your AI models always have access to the latest information. This is particularly useful for applications that require dynamic content generation based on current data, such as chatbots and recommendation systems.
- Scalable AI Deployments: Leveraging Firebase’s cloud infrastructure, Genkit enables scalable deployments of AI models. This means that as your application grows and user demand increases, the infrastructure can automatically scale to meet these needs without compromising performance.
- Simplified Data Management: With Firebase’s integrated data storage and management tools, developers can easily handle the data required for training and operating AI models. This includes capabilities for storing large datasets, real-time updates, and secure data handling.
To start using Firebase Genkit in your AI applications, follow these steps:
- Set Up Firebase: Create a Firebase project and set up your real-time database, storage, and authentication services.
- Install Genkit: Integrate Genkit into your project by following the installation instructions provided in the Genkit documentation.
- Configure Plugins: Add and configure the necessary Genkit plugins for data management, AI model integration, and user authentication.
Learn more about Firebase Genkit
Now let’s practice to learn more how we can build such an AI Solution!
Setting Up the Genkit HNSW Plugin
Prerequisites
Before installing the plugin, ensure you have the following installed:
- Node.js (version 12 or higher)
- npm (comes with Node.js)
- TypeScript (install globally via npm: npm install -g typescript)
- Genkit (install globally via npm: npm install -g genkit)
First thing first, initiate the Genkit project with
genkit init
follow the instructions here.
Once you have the Genkit project installed, make sure the project is well prepared. You can try first by
genkit start
If it runs well and open the Genkit UI in a browser, then you are good to go!
Installing the HNSW plugin
To install the Genkit HNSW plugin, run the following command:
npm install genkitx-hnsw

We will be using 2 Genkit Plugins here.
- HNSW Indexer plugin
- HNSW Retriever plugin
1. HNSW Indexer Plugin
The HNSW Indexer plugin helps create a vector index from your data, which can be used as a knowledge reference for the HNSW Retriever.
Data Preparation
Prepare your data or documents, for instance, restaurant data, in a dedicated folder.

Registering the HNSW Indexer Plugin
Import the plugin into your Genkit project:
find genkit.config.ts file in your project, usually /root/src/genkit.config.ts.
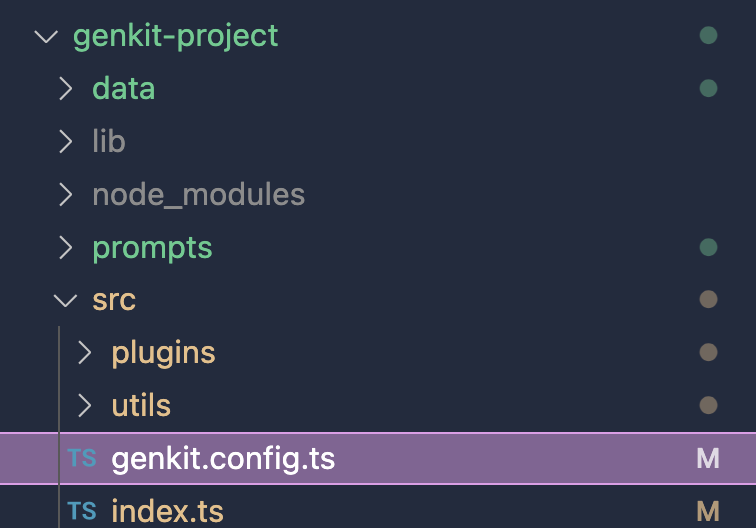
Then import the plugin into the file.
import { hnswIndexer } from "genkitx-hnsw";
//
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: "GOOGLE_API_KEY" })
]
});
Running the Indexer
- Open the Genkit UI and select the registered HNSW Indexer plugin.
- Execute the flow with the required parameters:
- dataPath: Path to your data and documents.
- indexOutputPath: Desired output path for the generated vector store index.
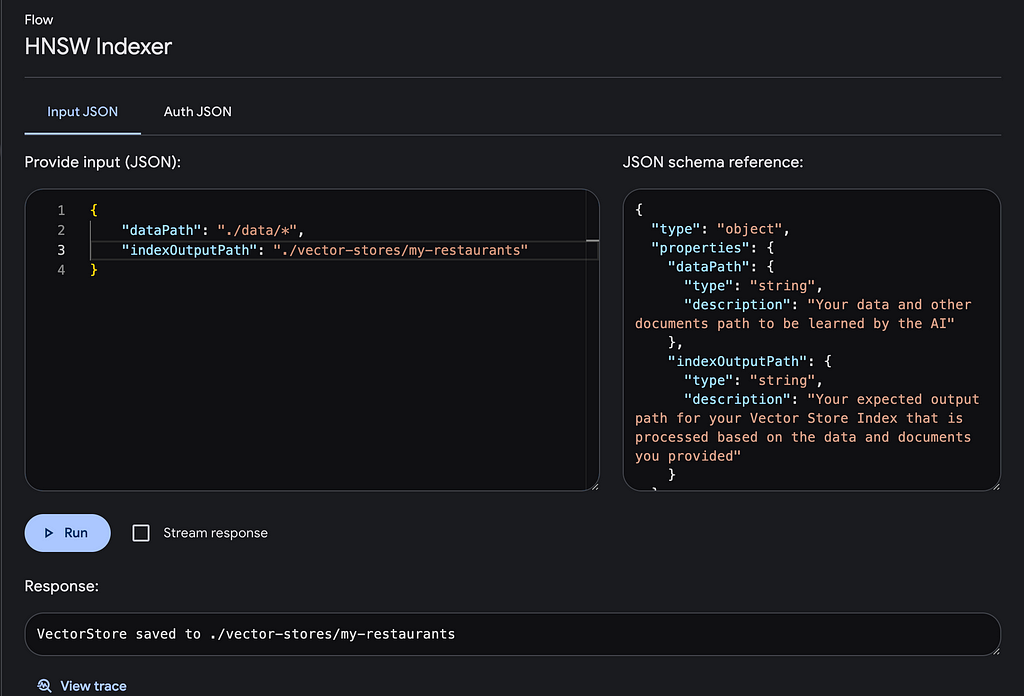
Vector Store Index Result
The HNSW vector store will be saved in the specified output path, ready for use with the HNSW Retriever plugin.
2. HNSW Retriever Plugin
The HNSW Retriever plugin processes prompt with the Gemini LLM Model, enriched with additional specific information from the HNSW Vector index.
Registering the HNSW Retriever Plugin
Import the necessary plugins into your Genkit project:
import { googleAI } from "@genkit-ai/googleai";
import { hnswRetriever } from "genkitx-hnsw";
export default configureGenkit({
plugins: [
googleAI(),
hnswRetriever({ apiKey: "GOOGLE_API_KEY" })
]
});
Running the Retriever
- Open the Genkit UI and select the HNSW Retriever plugin.
- Execute the flow with the required parameters:
- prompt: Your input query is for the AI.
- indexPath: Path to the vector index file generated by the HNSW Indexer plugin.
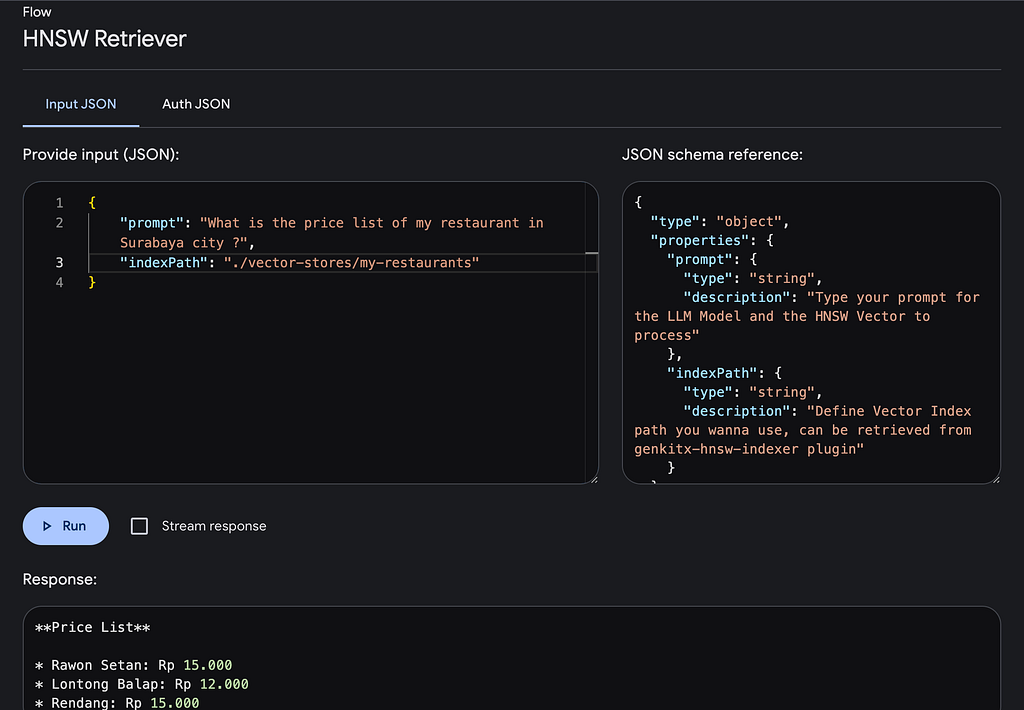
Example Prompt
To ask about the price list of a restaurant in Surabaya City:
prompt: "What is the price list of my restaurant in Surabaya City?"
indexPath: "/path/to/your/vector/index"
Conclusion
The integration of HNSW Vector index with Genkit significantly enhances the capabilities of Generative AI models by providing enriched context and specific knowledge.
This approach not only improves the accuracy of AI responses but also simplifies the process of knowledge integration, making it a powerful tool for various applications.
By following the steps outlined in this article, you can effectively leverage the HNSW Vector index to build more intelligent and context-aware AI systems in a very short time like instantly!
Hope this helps and see you in the next one!


Reliable AI Model Tuning : Leveraging HNSW Vector with Firebase Genkit was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
CInA: A New Technique for Causal Reasoning in AI Without Needing Labeled Data

Causal reasoning has been described as the next frontier for AI. While today’s machine learning models are proficient at pattern recognition, they struggle with understanding cause-and-effect relationships. This limits their ability to reason about interventions and make reliable predictions. For example, an AI system trained on observational data may learn incorrect associations like “eating ice cream causes sunburns,” simply because people tend to eat more ice cream on hot sunny days. To enable more human-like intelligence, researchers are working on incorporating causal inference capabilities into AI models. Recent work by Microsoft Research Cambridge and Massachusetts Institute of Technology has shown progress in this direction.
About the paper
Recent foundation models have shown promise for human-level intelligence on diverse tasks. But complex reasoning like causal inference remains challenging, needing intricate steps and high precision. Tye researchers take a first step to build causally-aware foundation models for such tasks. Their novel Causal Inference with Attention (CInA) method uses multiple unlabeled datasets for self-supervised causal learning. It then enables zero-shot causal inference on new tasks and data. This works based on their theoretical finding that optimal covariate balancing equals regularized self-attention. This lets CInA extract causal insights through the final layer of a trained transformer model. Experiments show CInA generalizes to new distributions and real datasets. It matches or beats traditional causal inference methods. Overall, CInA is a building block for causally-aware foundation models.
Key takeaways from this research paper:
- The researchers proposed a new method called CInA (Causal Inference with Attention) that can learn to estimate the effects of treatments by looking at multiple datasets without labels.
- They showed mathematically that finding the optimal weights for estimating treatment effects is equivalent to using self-attention, an algorithm commonly used in AI models today. This allows CInA to generalize to new datasets without retraining.
- In experiments, CInA performed as good as or better than traditional methods requiring retraining, while taking much less time to estimate effects on new data.
My takeaway on Causal Foundation Models:
- Being able to generalize to new tasks and datasets without retraining is an important ability for advanced AI systems. CInA demonstrates progress towards building this into models for causality.
- CInA shows that unlabeled data from multiple sources can be used in a self-supervised way to teach models useful skills for causal reasoning, like estimating treatment effects. This idea could be extended to other causal tasks.
- The connection between causal inference and self-attention provides a theoretically grounded way to build AI models that understand cause and effect relationships.
- CInA’s results suggest that models trained this way could serve as a basic building block for developing large-scale AI systems with causal reasoning capabilities, similar to natural language and computer vision systems today.
- There are many opportunities to scale up CInA to more data, and apply it to other causal problems beyond estimating treatment effects. Integrating CInA into existing advanced AI models is a promising future direction.
This work lays the foundation for developing foundation models with human-like intelligence through incorporating self-supervised causal learning and reasoning abilities.
CInA: A New Technique for Causal Reasoning in AI Without Needing Labeled Data was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Hyderabad’s Hyperleap AI Unveils Generative AI Platform After $225K Pre-Seed Round
How Experiential Etc is Shaping the Future with AI
AI-Powered Fitness Startup Portl Secures Major Investment from Leading Funds
Unlocking the Power of AI: Transforming Data into Actionable Insights
In the ever-evolving landscape of technology, the term “Artificial Intelligence” (AI) has become ubiquitous, often sparking discussions and debates about its true nature and potential. Regardless of the label — whether it’s AI, Artificial Intelligence, Deep Learning, Machine Learning (ML), or automation — these technologies are essentially a collection of algorithms that have the remarkable capability to extract valuable information from diverse data sources.

AI is a collection of algorithms that can extract valuable information from diverse data sources.
Imagine turning raw data, such as images, videos, sound recordings, sensor readings, documents, verbal inputs, emails, and more, into meaningful insights. These insights could range from identifying faulty elements in pictures, detecting scratches on surfaces, counting items in a container, diagnosing equipment issues from sound patterns, predicting maintenance needs based on sensor data, and recommending optimal energy-saving settings based on various factors. The possibilities are endless, and AI enables us to harness the full potential of data in various domains.
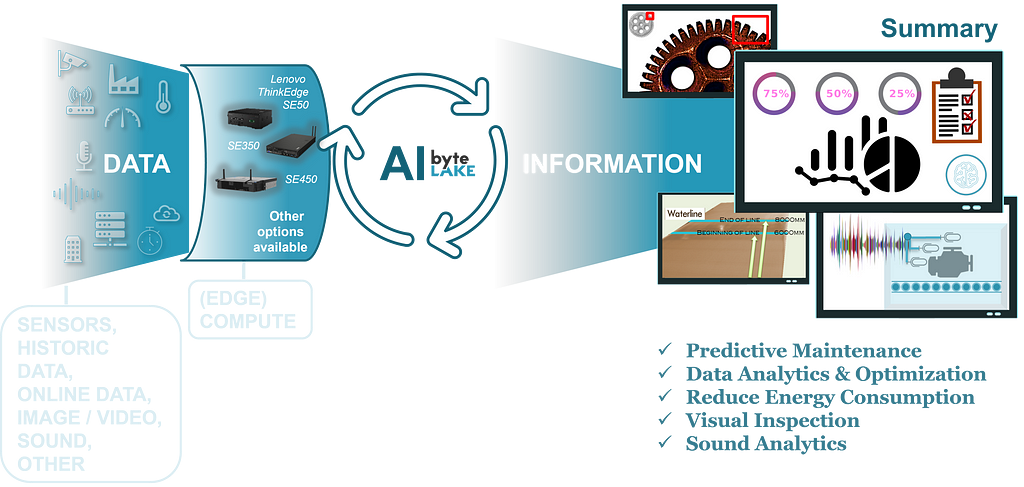
Once data is transformed into information, the next step is defining the scenario, which determines the action to be taken. This action could involve automation, where AI analyzes and processes data to streamline workflows, expedite processes, or enhance safety measures. Alternatively, AI can complement human efforts by providing insights, alerts, or recommendations to optimize performance, mitigate risks, or improve decision-making.
One remarkable application of AI lies in its ability to analyze complex simulations, such as those utilized in Computational Fluid Dynamics (CFD), chemical, or physical simulations. Instead of executing simulations step by step, AI can predict outcomes iteratively, accelerating the process and minimizing computational resources. By leveraging historical data from past simulations, AI learns and refines its predictions over time, unlocking new efficiencies and insights.
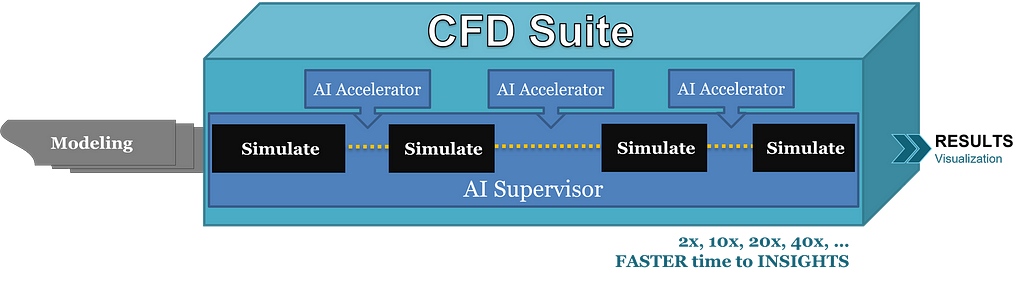
However, AI’s impact extends beyond simulation acceleration. It can also revolutionize the entire simulation process by assisting in preparation, configuration optimization, and result analysis. By analyzing past simulations and learning from them, AI can guide engineers in prioritizing simulations, reducing trial and error, and optimizing parameters. This holistic approach enhances efficiency and effectiveness across the simulation lifecycle.
AI can guide engineers in prioritizing simulations, reducing trial and error, and optimizing parameters.
While it makes sense and is usually economically justified (despite overhead related to AI training) to AI-accelerate relatively small, steady-state simulations with predictable parameters, larger, more complex simulations involving tens or hundreds of millions of cells, transient conditions, or frequently changing geometries create a different landscape for AI.
To justify the cost of AI training, we need to go beyond single-simulation acceleration. Again, by leveraging historical data and learning from past simulations, AI can predict outcomes but what is more important, it can also suggest optimal configurations, and streamline the entire simulation workflow. Whether it’s analyzing inputs, assessing outcomes, optimizing parameters, or providing insights, AI serves as a powerful ally in navigating the complexities of CFD simulations.

Through harnessing the power of IoT-generated data, AI becomes a predictive force, foreseeing maintenance needs, uncovering error origins, and recommending energy-saving strategies, fostering efficiency and sustainability across diverse infrastructures.
The synergy between CFD Suite and Data Insights within the energy sector illustrates the transformative potential of AI, mathematics, and creativity. While cameras capture visual data and IoT devices provide real-time inputs and forecasts, the complexity of integrating these streams is immense. Yet, this complexity serves as fertile ground for human creativity. CFD Suite’s AI algorithms, adept at deciphering complex data structures, seamlessly adapt to the influx of information from industrial sensors and user inputs.
By synthesizing this data, CFD Suite becomes the central nervous system of modern infrastructure, capable of optimizing energy consumption and reducing waste across a spectrum of environments, from city-wide heating systems to individual appliances. This integration of CFD Suite and Data Insights heralds a new era of predictive maintenance and sustainable energy practices, underpinned by the boundless possibilities of AI-driven innovation.
In other words, imagine CFD Suite as the brain and Data Insights as the eyes and ears of the energy sector. Like a superhero duo, they work together to make everything smarter and more efficient. CFD Suite’s brainy algorithms can understand complex data, just like solving a puzzle. Meanwhile, Data Insights gathers information from cameras, sensors, and forecasts, like eyes and ears seeing and hearing what’s happening in real-time. When they team up, they can optimize energy use and reduce waste across cities and buildings. It’s like having a super-powered brain and senses working together to make our world greener, more sustainable, and reduce waste.

One common thread across all our AI products is Edge AI — deploying AI locally to process data and generate insights. This approach ensures real-time responsiveness, data privacy, and autonomy, empowering organizations to harness AI’s potential at the edge.
In conclusion, AI is not merely a buzzword; it’s a transformative force shaping the future of industries. While integrating AI into workflows may not be as straightforward as installing office software, the benefits are undeniable. As AI continues to evolve and mature, its applications will only become more diverse and impactful. If you’re interested in exploring AI solutions or have innovative ideas to share, don’t hesitate to reach out. The possibilities are limitless, and together, we can unlock the full potential of AI.
Unlocking the Power of AI: Transforming Data into Actionable Insights was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.