Humanity’s Upgrade — New Features Revealed
Humanity’s Upgrade — New Features Revealed
Our species has always been defined by the relentless push for improvement, and now, we are on the cusp of realizing what could be called Humanity 3.0. This next generation of human evolution promises transformations in every aspect of existence — from the biological to the societal, technological to the spiritual.
In this detailed analysis, I present future upgrades that may redefine what it means to be human. From leaps in longevity and augmented intelligence to profound societal shifts in governance and culture, I see a vision of an abundant future that draws on the threads of our past and the limitless potential of our present. These are not just incremental changes but are the harbingers of a new epoch for our species, a time when we take the reins of evolution itself into our hands.
Table 1: Humanity’s Evolutionary Upgrade: From Ancient to Modern to NextGen
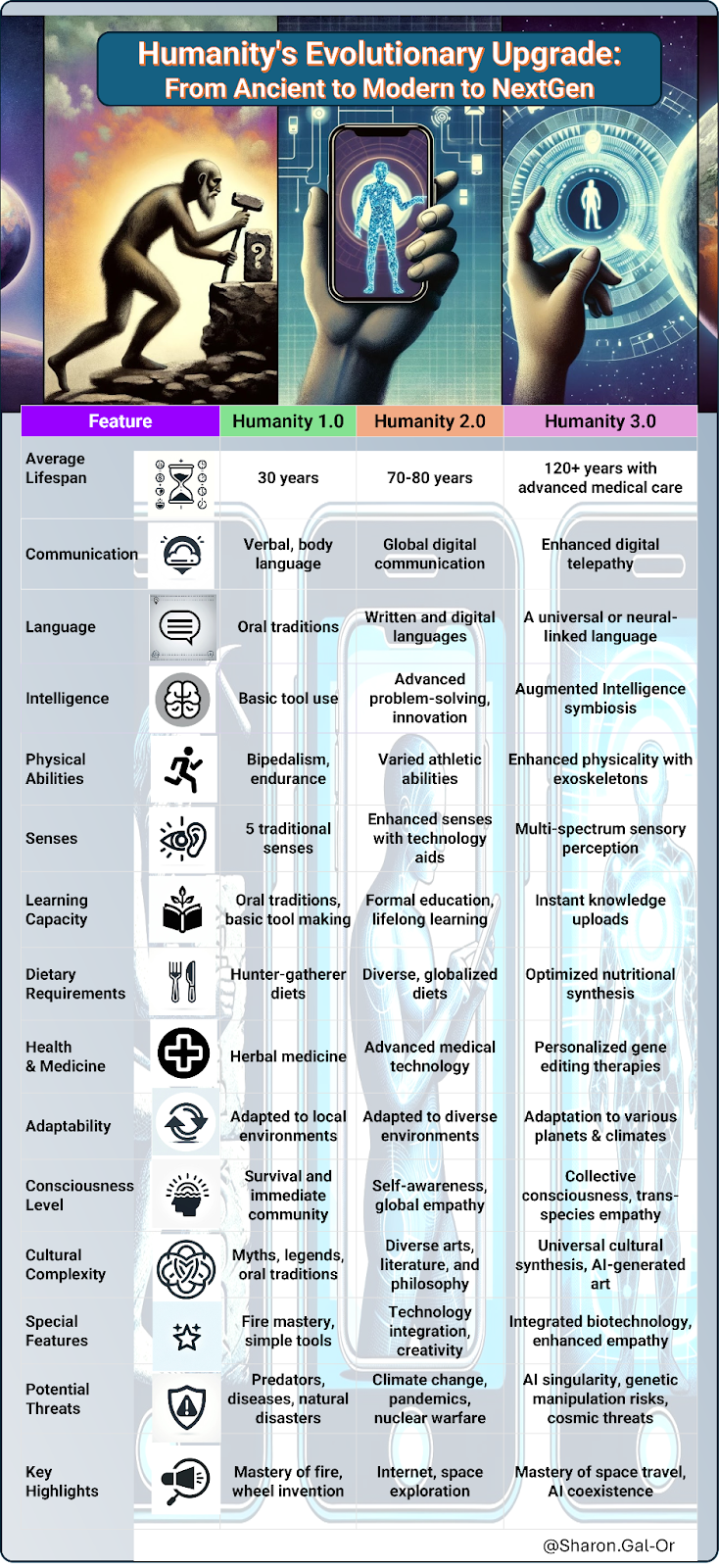
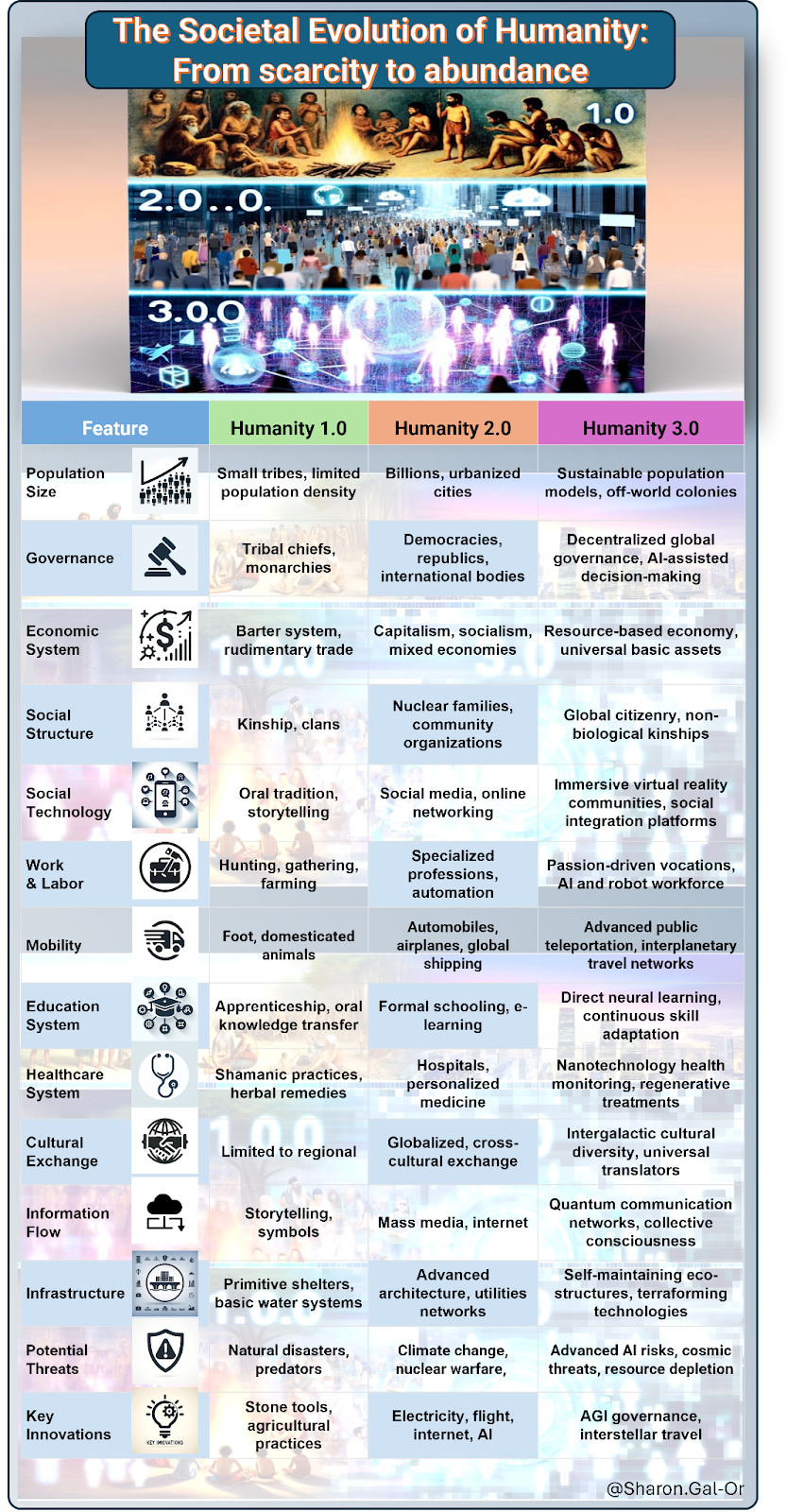
Table 2: The Societal Evolution of Humanity: From scarcity to abundance
Time Frame Index:
- Ancient Humanity 1.0: The dawn of civilization (around 10,000 BCE).
- Modern Humanity 2.0: The present day, extending slightly into the future (up to around 2100 CE).
- NextGen Humanity 3.0: From the late 21st century (post-2100 CE) onwards, focusing on speculative advancements and societal transformations.
In our journey through time, humanity has undergone remarkable transformations, not just biologically, but also in the way we organize and understand our societies. The evolution from Ancient to Modern to NextGen Humanity is marked by significant milestones that reflect our adaptability and ingenuity.
Ancient Humanity 1.0 was characterized by the emergence of agriculture, the development of early tools, and the formation of basic social structures. This era laid the groundwork for the complex societies that would follow.
Modern Humanity 2.0, our current era, has seen exponential growth in technology, communication, and global connectivity. We’ve built intricate economies, advanced healthcare systems, and diverse cultural landscapes. Yet, we stand on the brink of even more profound changes.
NextGen Humanity 3.0 envisions a future where technology and humanity are seamlessly integrated. We speculate on advancements such as enhanced longevity, augmented intelligence, DAO, and global unified communities. This era promises a redefinition of what it means to be human, as we extend our reach beyond Earth and redefine our place in the cosmos.
As we go through these evolutionary stages, I invite you all to reflect on our past, consider our present, and imagine our collective future. This journey is a testament to our resilience and a reminder of our potential to shape a world that reflects our highest aspirations.
My goal here was nothing more than a humble attempt to present a comprehensive overview of humanity’s evolution. Nonetheless, if you feel that a crucial feature has been overlooked or if you have suggestions for additional aspects that could enrich our understanding, I welcome your input. Your contributions may be considered for inclusion in future versions of this table. Together, we can build a more complete picture of our shared journey.
Join us as we explore the upgrades of tomorrow, painting a picture of a humanity more connected, more resilient, and more aware of its place in the cosmos than ever before as we enter the age of abundance.
Raising humanity on a new path — it all starts with You & AI I I…
Galorian
Humanity’s Upgrade — New Features Revealed was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Exploring the Top JavaScript Frameworks in 2024. A Detailed Review
Freshleaf raises INR 1 Crore in seed round led by IPV
Insured Mental Wellness: The Top Online Therapy Platforms of 2024
Humane’s AI Pin Struggles Lead to Potential Sale Talks, Insider Sources Reveal
Consumer Appliance Startup focuses on Sustainability values – Karban
AI Startup KonProz Receives $700K Funding to Expand Legal Tech and Team
5 Steps to Develop Your Chronic Care Management Program
